Presto SQL-不常用但很有用的函数
本文总结一下Presto SQL中不常用但很有用的函数,偶尔遇到相关需求时,能有Aha moment效果。
1. JSON函数
有些数据可能是以JSON字符串的形式存储的,比如APP埋点数据、用户行为数据等,将不同的信息同时记录在一个字段中,但我们在做数据分析时,可能只需要其中的一两类信息,此时就需要从JSON字符串中只抽取我们需要的信息,Presto SQL中就有对应的函数:
json_extract(json, json_path) → json
从JSON字符串中抽取目标信息,注意返回值是JSON类型不是字符串。
json_extract_scalar(json, json_path) → varchar
从JSON字符串中抽取目标信息,返回值是字符串,因此更好用一点。
应用举例→
示例代码:
select
postal_info,
json_extract(postal_info,'.calle') as calle1, json_extract_scalar(postal_info,'.calle') as calle2
from cust_info
limit 1;
结果如下:

示例代码:
select
data_content,
json_extract_scalar(json_extract(json_extract(data_content,'.data'),'.deviceInfo'),'.uuid') as uuid1,
json_extract_scalar(data_content,'.data.deviceInfo.uuid') as uuid2 --多层嵌套的时候用这种写法
from apply_info
where module_code='deviceInfo'
limit 1;
结果如下:

2. 正则函数
有时候需要清洗规整数据,比如抽取特定内容、去除特殊字符等,此时选用正则函数会更高效。Presto SQL中就有对应的函数:
regexp_extract(string, pattern) → varchar
从目标字符串中抽取第1个符合给定的正则表达式模式的子字符串,返回值类型是varchar。
regexp_extract_all(string, pattern)
从目标字符串中抽取所有符合给定的正则表达式模式的子字符,返回值是数组。
应用举例→
示例代码:
select
'中国有32个省和14亿人口' as string1,
regexp_extract('中国有32个省和14亿人口', '\d+') as string2,
regexp_extract_all('中国有32个省和14亿人口', '\d+') as string3,
regexp_extract_all('中国有32个省和14亿人口', '\d+')[1] as string4,
regexp_extract_all('中国有32个省和14亿人口', '\d+')[2] as string5
结果如下:

regexp_replace(string, pattern, replacement) → varchar
替换目标字符串中所有符合给定的正则表达式模式的子字符串。
应用举例→
示例代码:
select
'1a 2b 14m' as string1,
regexp_replace('1a 2b 14m', '\d+[ab] ') as string2, --将 以数字开头以a或b结尾的子字符 替换为空
regexp_replace('1a 2b 14m', '\d+') as string3, --将数字都去除
regexp_replace('1a 2b 14m', '[^0-9]') as string4, --只保留数字
regexp_replace('1a 2b 14m', '\d', '0') as string5, --将数字都替换为0
regexp_replace('1a 2b 14m', '\n') as string6 --去除换行符
结果如下:

regexp_like(string, pattern) → boolean
支持正则表达式的like,判断目标字符串中是否包含符合给定的正则表达式模式的子字符串,返回值类型是boolean。
在 like 条件判断比较多的时候,也就是需要写较多的 or like 时,可以考虑使用 regexp_like() 。
应用举例→
示例代码:
select
'浙江省杭州市310002' as string,
regexp_like('浙江省杭州市310002','\d+') as is_contained1, --是否包含数字
regexp_like('浙江省杭州市310002','杭州') as is_contained2, --是否包含杭州
regexp_like('浙江省杭州市310002','上海') as is_contained3, --是否包含上海
regexp_like('浙江省杭州市310002','北京|上海|广州|深圳|杭州') as is_contained4 --是否包含北京上海广州深圳杭州
结果如下:

3. 数组函数
在需要合并行内容时,就需要使用数组函数了。Presto SQL中常用的数组函数有以下几个:
array_agg(x) → array<[same as input]>
将字段值拼成数组的聚合函数,返回值类型是数组。
array_distinct(x) → array
对数组去重,移除数组中重复的值,返回值类型是数组。
array_join(x, delimiter, null_replacement) → varchar
将数组中的元素按照给定的分隔符进行拼接组成新的字符串,返回值类型是varchar。
应用举例→
我们有这样一份源数据:
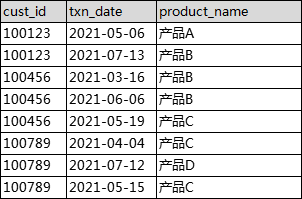
示例代码:
select cust_id, array_agg(product_name) as all_product_name1, array_distinct(array_agg(product_name)) as all_product_name2, array_join(array_distinct(array_agg(product_name)), ',') as all_product_name3 from tmp.tmp_ws_test_01 group by 1;
结果如下:

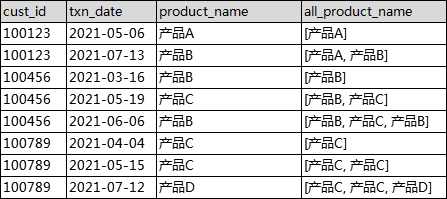
示例代码:
select
cust_id,
txn_date,
product_name,
array_agg(product_name) over (partition by cust_id order by txn_date) as all_product_name
from tmp.tmp_ws_test_01
order by 1,2;
结果如下:
原创文章,欢迎转载,转载请注明出处并留下原文链接。