Python简易爬虫1-电影票房排行榜
最近我在做行业市场分析时,正好有爬取数据的需求。之前我觉得爬虫没什么用,一是因为我们很少用到外部数据,平时都是基于内部业务数据做分析,二是因为爬虫相关的政策法规越来越严格,一不小心就触犯法律了,但我现在觉得爬虫还是有用的,尤其是在做行业市场分析、竞品分析等需要用到外部数据的时候。因此,笔者总结下 Python简易爬虫 的实现,以便我自己和大家在需要时有所参考。
1. 确定爬取目标
我们的爬取目标是很简单的电影票房排行榜,我们要爬取网站上的表格数据,网站信息如下:
内容:
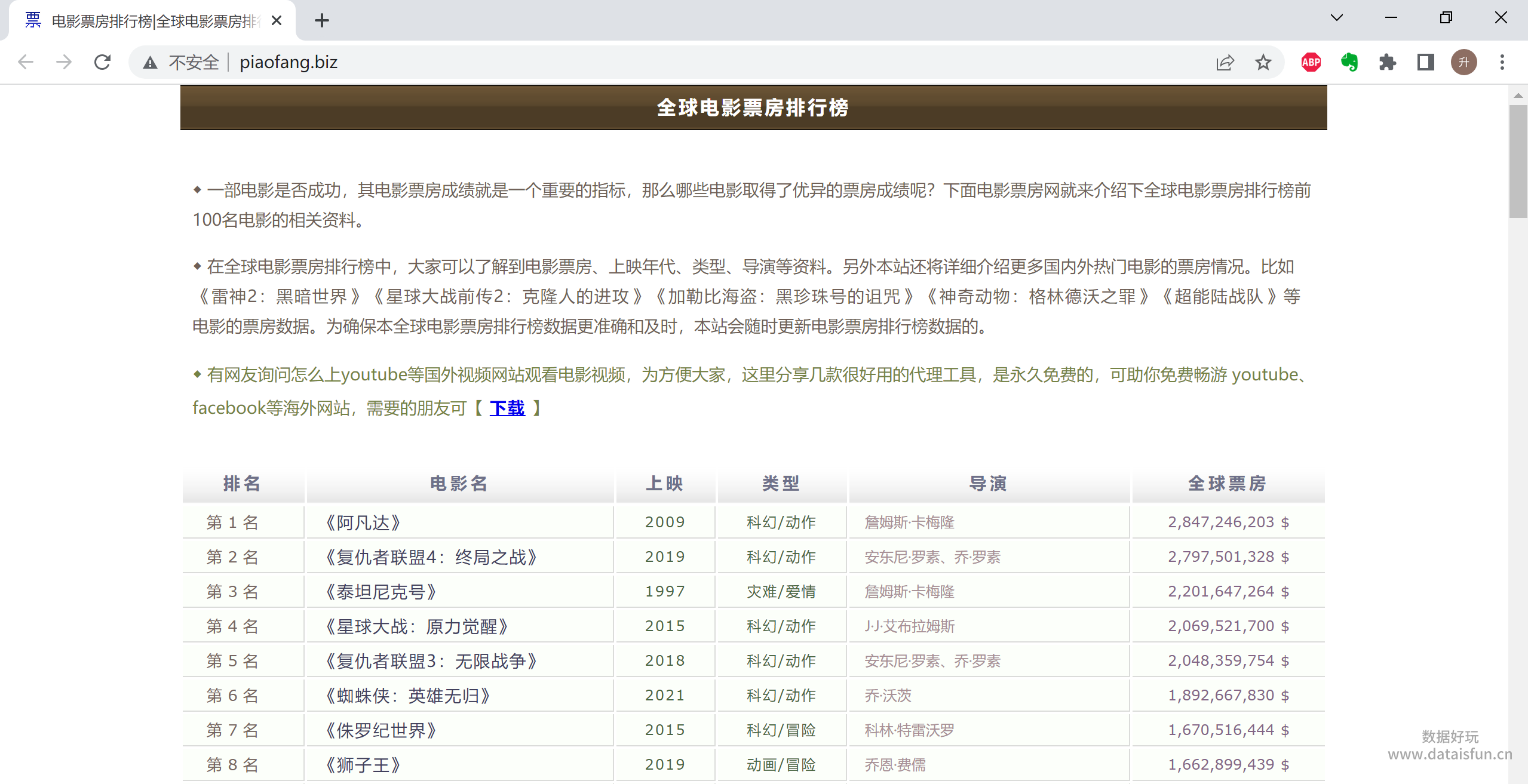
2. 分析数据源
我们在Chrome浏览器中打开网址,右键检查,一是确定网页所用的编码,网页使用的编码为gb2312,二是确定数据的具体位置,数据存储在<table>标签中。
3. 开发代码
# 导入要用的包
import numpy as np
import pandas as pd
import re
import requests
from bs4 import BeautifulSoup
# 请求数据
response = requests.get("http://www.piaofang.biz")
response.encoding = 'gb2312' # 目标网站使用的编码
# 解析数据
text = BeautifulSoup(response.text, "html.parser")
# 获取数据
table = text.find("table") # 提取table标签
trs = table.find_all("tr") # 数据存在tr标签里,一个tr代表一条数据,提取tr标签
tr_list = []
for tr in trs:
tds = tr.find_all("td") # td标签中存储了电影信息,提取td标签
if len(tds) != 0:
td_list = []
for td in tds:
td_list.append(td)
tr_list.append(td_list)
resource = pd.DataFrame(tr_list, dtype='str') # 将数据转成DataFrame类型
# 清洗数据
resource.to_excel("resource.xlsx") # 导出并观察字符串特征以便后续使用正则清洗数据
data = resource.copy()
data.drop(0, inplace=True) # 删除首行
data[0] = data[0].str.extract(r"(\d+)", expand=False).astype('int8')
data[101] = data[1].str.extract(r"《(.*)》", expand=False)
data[102] = data[101].str.extract(r">(.*)<", expand=False)
data.loc[data[102].isnull(),102] = data[101]
data[2] = data[2].str.extract(r">(.*)<", expand=False)
data[3] = data[3].str.extract(r">(.*)<", expand=False)
data[4] = data[4].str.extract(r">(.*)<", expand=False)
data[5] = data[5].str.extract(r"<span>(.*)</span>", expand=False)
data[5] = data[5].str.replace(",","").astype('int64')
data = data[[0, 102, 2, 3, 4, 5]]
data.columns = ['排名', '电影名', '上映时间', '类型', '导演', '全球票房'] # 重命名列
# 存储数据
data.to_excel("data.xlsx") # 清洗完成后重新导出到本地
4. 小结
这个Case的代码是比较简单的,因为这个网站非常简单,数据存储使用标准的html标签形式,我们使用BeautifulSoup解析并逐层提取标签内容后再用正则表达式清洗提取目标数据就行了,非常适合入门练手。
原创文章,转载请务必注明出处并留下原文链接。