SQL-经典的行列转换问题
行列转换是数据处理中常见的操作,日常报表经常需要按照业务看数习惯做行列转换,因此,本文总结一下SQL行列转换的实现。
行列转换包括行转列和列转行:
- 行转列:由行变成列,行变少列变多
- 列转行:由列变成行,列变少行变多
假设我们有如下 table1 和 table2 两张汇总表(不重复),table1 → table2 即为行转列,table2 → table1 即为列转行,我们看一下Presto SQL行转列、列转行的实现。
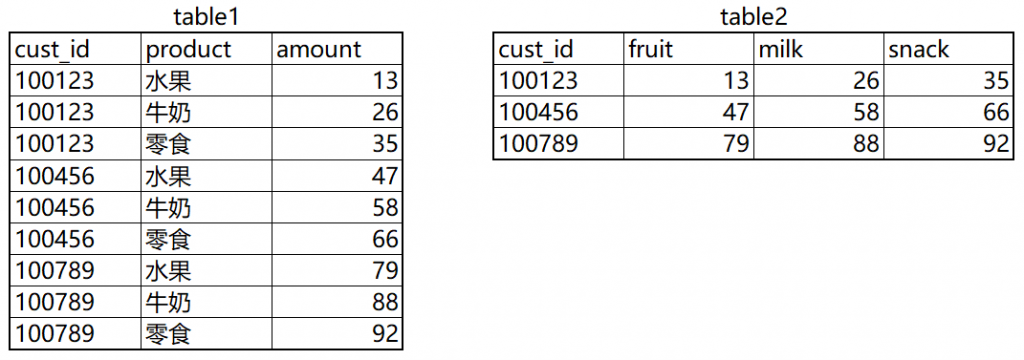
table1 → table2 行转列:
--行转列_使用case when实现 select cust_id, sum(case when product = '水果' then amount end) as fruit, sum(case when product = '牛奶' then amount end) as milk, sum(case when product = '零食' then amount end) as snack from table1 group by 1; --行转列_使用map实现 select cust_id, kv['水果'] as fruit, kv['牛奶'] as milk, kv['零食'] as snack from ( select cust_id, map_agg(product, amount) as kv from table1 group by 1 );
table2 → table1 列转行:
--列转行_使用cross join unnest实现 select cust_id, product, amount from table2 cross join unnest( array['fruit', 'milk', 'snack'], array[fruit, milk, snack] ) as t (product, amount);
以上的行转列、列转行即是我们通常所说的行列转换,不过实际取数中还有一种”列转行”-将单行内容转成多行内容,这是因为源表在存储数据时将数据合并存储了。 假设我们有如下 table3 和 table4 两张表:
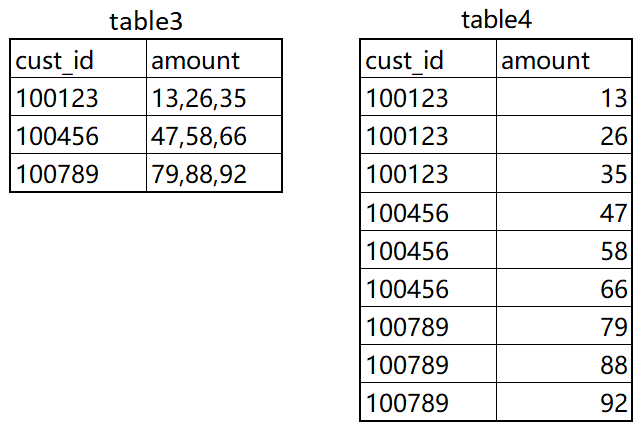
table3 → table4 单行转多行:
--单行转多行_使用cross join unnest实现
select
cust_id,
amount_split as amount
from table3
cross join unnest(split(amount, ',')) as t (amount_split);
对于业务固化的报表而言,无论是行转列还是列转行,都是必要的。但对于分析而言,多维度汇总表保留的信息量更多、伸缩性扩展性更强,在取数过程中,行转列是不必要的,列转行是必要的,我们可以在SQL中跑出多维度汇总的源表后,继续在Excel中或者在Python中做各种透视分析。
原创文章,欢迎转载,转载请注明出处并留下原文链接。