SQL-比较两个字符串相同的位数
最近遇到了一个取数场景–比较两个字符串有多少位相同,之所以有这个需求,是因为一个是OCR识别的,一个是用户输入的,需要比对分析下从而做出改进。下面就总结下 SQL比较两个字符串相同的位数 具体如何实现:
假设我们已有如下源表 table1,我们要得到字段 info_ocr 和字段 info_input 相同的位数和不同的位数:
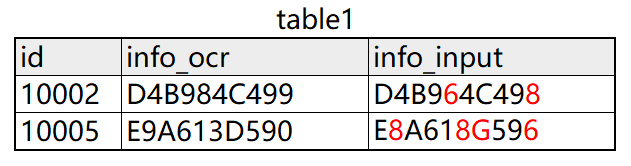
示例代码:
--方法1:截取字符并逐一比较
select
id,
info_ocr,
info_input,
case when substr(info_ocr, 1, 1) = substr(info_input, 1, 1) then 1 else 0 end
+ case when substr(info_ocr, 2, 1) = substr(info_input, 2, 1) then 1 else 0 end
+ case when substr(info_ocr, 3, 1) = substr(info_input, 3, 1) then 1 else 0 end
+ case when substr(info_ocr, 4, 1) = substr(info_input, 4, 1) then 1 else 0 end
+ case when substr(info_ocr, 5, 1) = substr(info_input, 5, 1) then 1 else 0 end
+ case when substr(info_ocr, 6, 1) = substr(info_input, 6, 1) then 1 else 0 end
+ case when substr(info_ocr, 7, 1) = substr(info_input, 7, 1) then 1 else 0 end
+ case when substr(info_ocr, 8, 1) = substr(info_input, 8, 1) then 1 else 0 end
+ case when substr(info_ocr, 9, 1) = substr(info_input, 9, 1) then 1 else 0 end
+ case when substr(info_ocr, 10, 1) = substr(info_input, 10, 1) then 1 else 0 end as same_chr_cnt,
case when substr(info_ocr, 1, 1) <> substr(info_input, 1, 1) then 1 else 0 end
+ case when substr(info_ocr, 2, 1) <> substr(info_input, 2, 1) then 1 else 0 end
+ case when substr(info_ocr, 3, 1) <> substr(info_input, 3, 1) then 1 else 0 end
+ case when substr(info_ocr, 4, 1) <> substr(info_input, 4, 1) then 1 else 0 end
+ case when substr(info_ocr, 5, 1) <> substr(info_input, 5, 1) then 1 else 0 end
+ case when substr(info_ocr, 6, 1) <> substr(info_input, 6, 1) then 1 else 0 end
+ case when substr(info_ocr, 7, 1) <> substr(info_input, 7, 1) then 1 else 0 end
+ case when substr(info_ocr, 8, 1) <> substr(info_input, 8, 1) then 1 else 0 end
+ case when substr(info_ocr, 9, 1) <> substr(info_input, 9, 1) then 1 else 0 end
+ case when substr(info_ocr, 10, 1) <> substr(info_input, 10, 1) then 1 else 0 end as not_same_chr_cnt
from table1;
--方法2:将单行字符串拆成多行字符后判断并汇总
with
tmp1 as (
select
id,
info_ocr,
info_input,
info_ocr_chr,
row_number() over () as row_num
from table1
cross join unnest(split(info_ocr,'')) as t (info_ocr_chr)
),
tmp2 as (
select
id,
info_ocr,
info_input,
info_input_chr,
row_number() over () as row_num
from table1
cross join unnest(split(info_input,'')) as t (info_input_chr)
),
tmp3 as (
select
tmp1.id,
tmp1.info_ocr,
tmp1.info_input,
tmp1.info_ocr_chr,
tmp2.info_input_chr,
case when tmp1.info_ocr_chr = tmp2.info_input_chr then 1 else 0 end as is_chr_same
from tmp1
left join tmp2
on tmp1.id = tmp2.id and tmp1.row_num = tmp2.row_num
)
select
id,
info_ocr,
info_input,
sum(is_chr_same) as same_chr_cnt,
10 - sum(is_chr_same) as not_same_chr_cnt
from tmp3
where info_ocr_chr <> ''
group by 1,2,3;
代码结果:

以上就是 SQL比较两个字符串相同的位数或不同的位数 的代码实现,方法1更直观通用,方法2也是一种思路,代码使用Presto SQL执行,其他SQL语言可能会略有差异。
原创文章,欢迎转载,转载请注明出处并留下原文链接。